Using ML.NET to have a safe trip on Titanic
GitHub url: https://github.com/sbaidachni/MLNETTitanic
Couple years ago, I participated in a series of events for students, where we made some demos about Machine Learning Studio. The centerpiece of the demo was a model that could help make prediction about your chance to survive on Titanic. The datasets to build the model are still available on Kaggle, and you can download them using the following link: DataSets. That’s why, when Microsoft announced a new machine learning library for .NET developers, I decided to start playing with it using exactly the Titanic datasets. Let’s do it together.
ML.NET is an open-source and cross-platform framework for .NET developers. It means that you can use it on Windows, Mac, Linux platforms utilizing .NET Core power, but it should also work on .NET Framework. For my demo I am going to use exactly .NET Framework, because I found that package installation is more challenging there compare to .NET Core. So, let’s create a basic Console application and use NuGet package manager to add Microsoft.ML package to the project:
I am going to use the latest stable release to simplify my post, but you can clone GitHub repository and build all needed assemblies from the source. I would recommend to use this approach if you want to get access to all new features. Looks like that many developers are contributing to the project right now to make a product that is too close to Microsoft internal machine learning library. For example, the current version (0.1.0) doesn’t allow you to split a dataset for training/testing parts and integrate it to a pipeline. It’s possible to split, but you need to go one level down rather than use high level Pipeline API. At the same time, if you compile the latest version of the library you will be able to see that there is an improvement regarding to cross-validation in the pipeline that is implemented already and it should be available in the [next release] (https://github.com/dotnet/machinelearning/issues/6).
Adding the Microsoft.ML package to .NET Framework project you will need to make sure that your current platform is 64-bits. ML.NET doesn’t work on 32-bits (at least, right now), and to avoid any issues you can use Project Properties (Build tab) to choose the platform explicitly:

Working in .NET Framework environment I found couple small issues (not reproduced for .NET Core). The first one is System.ValueTuple assembly that was included to my project, but for .NET Framework 4.7.1 projects all tuple related functionality already included to mscorlib. So, if you use tuples, you will need to remove this library manually. The second problem is related to two native libraries CpuMathNative.dll and FastTreeNative.dll. Both libraries were copied to my solution folder, but Visual Studio cannot see them by default. The simplest way to fix the problem (you will have a runtime exception) is just copied both libraries to bin folder with your application. If you create .NET Core application rather than .NET framework it just works without modifications above.
Finally, we need to prepare train and test datasets. You need to download just train.csv dataset from Kaggle. They have test.csv, but this dataset doesn’t contain labels and should be used to participate in Kaggle competition (to predict labels using your model and send results to Kaggle). So, we will need to split train.csv to have some data for evaluation. As I mentioned earlier, splitting is not integrated with pipeline in 0.1 version. So, I use a simple R script to make this task (included to the solution as a separate project). Once you have train/test sets you can place them anywhere and use absolute paths or include them to the project. If you included the sets to the project, don’t forget to change file properties to copy both of them to your application folder:

Ok. Let’s start coding.
ML.NET contains the TextLoader class that allows you to read data from csv files. But it’s not just a stupid text reader. Thanks to TextLoader you can make conversion, rename columns and drop some of them on fly. The Titanic dataset contains 12 columns (their descriptions on Kaggle) and I strongly believe that PassengerId and Name columns cannot affect my model. The PassengerId column is just a row number in our dataset. Obviously, this number in our dataset would not help people to survive. Name doesn’t help to survive as well. So, I decided to drop these columns since the beginning. At the same time the dataset contains a very important column called Survived. This is our label, and I need to rename it to Label, because Label and Features are default names for ML.NET pipeline. In order to describe all these changes to TextLoader, we need to define a class. Below you can find an example of this class:
public class Passenger
{
[Column(ordinal:"1", name:"Label")]
public bool Survived;
[Column(ordinal: "2")]
public float Pclass;
[Column(ordinal: "4")]
public string Sex;
[Column(ordinal: "5")]
public float Age;
[Column(ordinal: "6")]
public float SibSp;
[Column(ordinal: "7")]
public float Parch;
[Column(ordinal: "8")]
public string Ticket;
[Column(ordinal: "9")]
public float Fare;
[Column(ordinal: "10")]
public string Cabin;
[Column(ordinal: "11")]
public string Embarked;
}
public class PredictedData
{
[ColumnName("PredictedLabel")]
public bool IsSurvived;
}
You can see that there is the Column attribute that allows us to define the column name and specify its position in the dataset. There are three data types: bool, string and float. Potentially, I could use int for some columns, but ML.NET doesn’t support this data type now.
One more class that I defined above is PredictedData. This is a container that we are going to use making prediction. In our case we have just two-class classification task. So, I could use bool. Additionally, I applied the ColumnName attribute to make sure that ML.NET will recognize the field to store predicted values.
Before to start training our model we need to prepare data first like clean missing values, convert string columns to numeric vectors and so on. What is more important, once you train your model on your prepared data, you will need to do the same transformations with testing dataset and all data that you are using to make predictions. That’s why modern frameworks allow developers to combine a model parameters and pipeline information inside the model. Using this approach you can load the model, pass initial data and the model will preprocess them “automatically” before make prediction. To build own pipeline in ML.NET we can use the LearningPipeline class.
var pipeline = new LearningPipeline();
This class allows us to combine all preprocessing steps prior the training and include all these steps to the model. Below you can find and example of a pipeline for our dataset:
pipeline.Add(new TextLoader(trainSetPath, useHeader: true, separator: ","));
pipeline.Add(new ColumnDropper() {Column=new string[] {"Cabin","Ticket"} });
pipeline.Add(new MissingValueSubstitutor(new string[] { "Age" })
{ ReplacementKind=NAReplaceTransformReplacementKind.Mean });
pipeline.Add(new CategoricalOneHotVectorizer("Sex", "Embarked"));
pipeline.Add(new ColumnConcatenator(
"Features", "Age","Pclass", "SibSp","Parch","Sex","Embarked"));
pipeline.Add(new FastTreeBinaryClassifier());
You can see that we need to start with a TextLoader to have some data for preprocessing and training. After that I decided to drop two more columns to save some space in computer memory. Both columns Cabin and Tickets contain some random text and I don’t have any ideas how to utilize these fields.
Right after that I decided to clean Age field. This column contains many missing values, but it’s not wisely to drop all rows where Age is missing, because I will not have enough data to train/test my model. So, I replace all missing values with mean. You can drop this column at all and see difference.
One more step is converting text categorical fields to one hot numeric vectors. I used CategoricalOneHotVectorizer and added it to the pipeline.
Finally, we need to concatenate all numeric columns to just one called Features. It’s a default name like Label. Once it’s done I can add a classifier. In this case I used fast tree, but there are couple more to make some experiments.
The LearningPipeline class is optimized for debugging, and if you run the code above, you will be able to see how your data is transforming on each step:
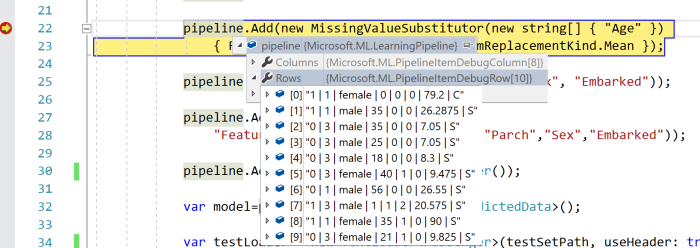
Now, I can train my model using defined above pipeline. This step is not challenging at all:
var model=pipeline.Train();
Once model is trained, you can save it to your disc using WriteAsync, load from the disk using LoadAsync or start making predictions using the Predict method. But I still want to evaluate my model. In order to do it we can use the BinaryClassificationEvaluator class and one more TextLoader to load our test dataset:
var testLoader = new TextLoader(testSetPath, useHeader: true, separator: ","); var evaluator = new BinaryClassificationEvaluator(); var metrics=evaluator.Evaluate(model, testLoader);
Below you can see some data from metrics object:

So, you can see that accuracy and F1 Score is pretty good and we still have some room for improvement. For example, we can make our training using the full training dataset and use cross-validation approach for evaluation, we can provide some parameters to the classifiers, we can improve Age cleansing procedure and so on. In any case, you can see that our code is not complex at all and you can make lots of experiments just tuning parameters.
If you are interested in ML.NET, I would recommend to clone the project from GitHub to use the latest updates. Good luck with your experiments.


Leave a comment